mybatis-plus
简介
MyBatis-Plus (简称 MP)是一个 MyBatis 的增强工具,在 MyBatis 的基础上==只做增强不做改变==,为简化开发、提高效率而生。(先了解[[mybatis]]框架)
1.快速开始
1.1 导入依赖
导入mybatis-plus依赖,包含了mybatis,==不用额外再导入mybatis依赖==
<dependency > <groupId > com.baomidou</groupId > <artifactId > mybatis-plus-boot-starter</artifactId > <version > 3.5.3.1</version > </dependency >
1.2 创建Mapper
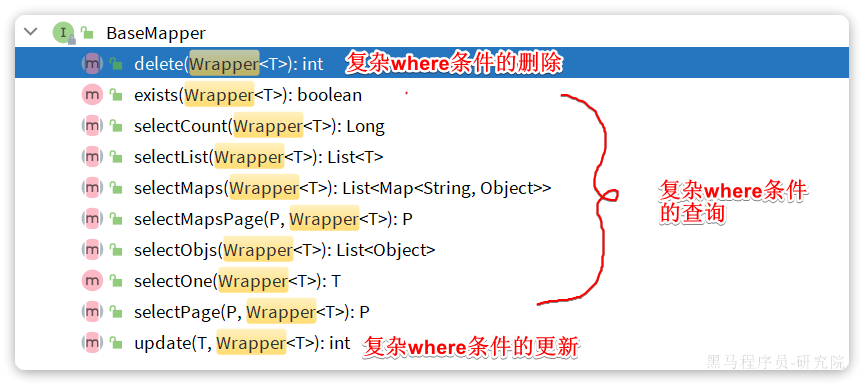
为了简化单表CRUD,mp已经提供了对于单表的CRUD操作的接口BaseMapper,直接继承BaseMapper接口即可直接使用
1.3 测试CRUD
测试BaseMapper中对单表CRUD操作
@Test public void testInsert () {User user = new User ();"ikun23" );"123" );"18688990011" );200 );24 ,"英语老师" ,"female" ));@Test public void testSelectById () {User user = userMapper.selectById(4L );@Test public void testSelectByIds () {1 , 2 , 3 ));@Test public void testUpdate () {User user = new User ();5L );3 );24 ,"英语老师" ,"female" ));@Test public void testDelete () {5L ));
总结:只要继承了BaseMapper,就能直接对单表进行CRUD操作!
2.常见注解
问题 :在刚刚的测试中,我们直接调用BaseMapper中的方法就能对表增删改查,在继承BaseMapper的时候我们只是指定了一个泛型<User>,并没有指定是哪张表,那么==mybatis-plus怎么知道我们要操作的是user表呢?它又是怎么知道这张表中的所有字段名呢?==
解答:其实mp遵从==约定大于配置==的思想,mp从User类推导出数据库中表名为user,然后根据User类中的所有变量名从==驼峰命名==转成==下划线==作为数据库的字段名,从而在调用方法时可以自动生成正确的sql语句。
如果我们在创建User类和user表的时候遵从驼峰命名和下划线命名,那么我们不需要做额外的配置,如果类名和表名、属性名和字段名直接不是简单的转换,那么我们就不得不使用一些相应的注解来声明表的信息
描述:表名注解,标识实体类对应的表
使用位置:实体类
@TableName("sys_user") public class User {private Long id;private String name;private Integer age;private String email;
@TableName("sys_user") public class User {@TableId private Long id;private String name;private Integer age;private String email;
属性 类型 必须指定 默认值 描述
value
String
否
“”
主键字段名
type
Enum
否
==IdType.NONE==
指定主键类型
IdType支持的类型有:
值 描述
AUTO
数据库 ID 自增
NONE
无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT)
INPUT
insert 前自行 set 主键值
ASSIGN_ID
分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法)
ASSIGN_UUID
分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法)
ID_WORKER 分布式全局唯一 ID 长整型类型(please use ASSIGN_ID)
UUID 32 位 UUID 字符串(please use ASSIGN_UUID)
ID_WORKER_STR 分布式全局唯一 ID 字符串类型(please use ASSIGN_ID)
这里比较常见的有三种:
AUTO:利用数据库的id自增长INPUT:手动生成idASSIGN_ID:雪花算法生成Long类型的全局唯一id,这是默认的ID策略
@TableName("sys_user") public class User {@TableId private Long id;@TableField("nickname") private String name;private Integer age;private String email;
3.常见配置
MybatisPlus也支持基于yaml文件的自定义配置,详见官方文档:使用配置 | MyBatis-Plus
大多数的配置都有默认值,因此我们都无需配置。但还有一些是没有默认值的,例如:
mybatis-plus: type-aliases-package: com.itheima.mp.domain.po global-config: db-config: id-type: auto
需要注意的是,MyBatisPlus也支持手写SQL的,而mapper文件的读取地址可以自己配置:
mybatis-plus: mapper-locations: "classpath*:/mapper/**/*.xml"
可以看到默认值是classpath*:/mapper/**/*.xml,也就是说我们只要把mapper.xml文件放置这个目录下就一定会被加载。
使用@MapperScan注解标识mapper类所在目录
@SpringBootApplication @MapperScan("com.clb.mapper") public class App {public static void main (String[] args) {
配置了==@MapperScan==注解后,mapper类中无需添加==@Mapper==注解
4.核心功能
4.1 条件构造器
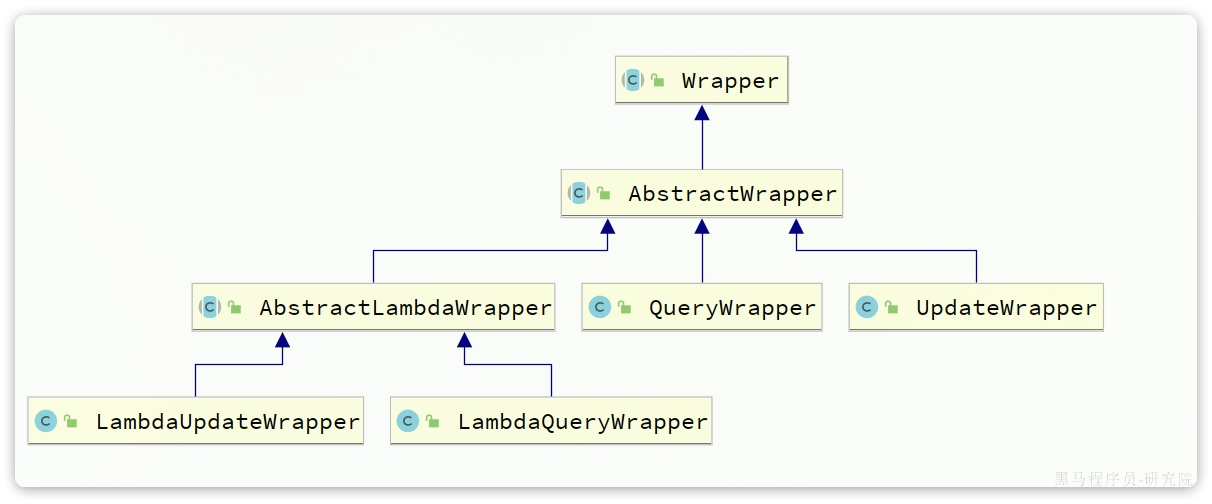
除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法除了以id作为where条件以外,还支持更加复杂的where条件。Wrapper就是条件构造的抽象类,其下有很多默认实现,继承关系如图:
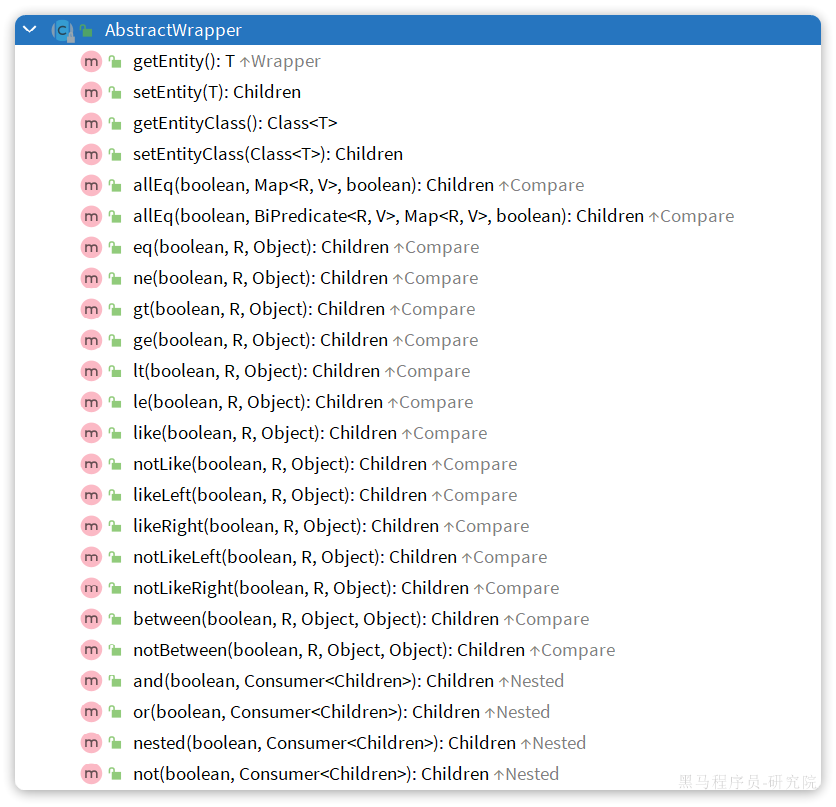
Wrapper的子类AbstractWrapper提供了where中包含的所有条件构造方法:
接下来,我们就来看看如何利用Wrapper实现复杂查询。
4.1.1 QueryWrapper
修改、删除、查询都可以使用QueryWrapper构建查询条件
**查询:**查询名字带有o,且存款大于等于1000的人
select id,username,info,balance from user where username like % o% and balance >= 1000 ;
@Test public void test02 () {new QueryWrapper <>();"id" , "username" , "info" , "balance" )"username" , "o" )"balance" , 1000 );
4.1.2 UpdateWrapper
基于BaseMapper中的update方法更新时只能直接赋值,对于一些复杂的需求就难以实现。1,2,4的用户的余额,扣200,对于的SQL应该是:
UPDATE user SET balance = balance - 200 WHERE id in (1 , 2 , 4 )
SET的赋值结果是基于字段现有值的,这个时候就要利用UpdateWrapper中的setSql功能了:
@Test void testUpdateWrapper () {1L , 2L , 4L );new UpdateWrapper <User>()"balance = balance - 200" ) "id" , ids); null , wrapper);
4.1.3 LambdaQueryWrapper
无论是QueryWrapper还是UpdateWrapper在构造条件的时候都需要写死字段名称,可能会出现字符串写错的现象,因此MybatisPlus又提供了一套基于Lambda的Wrapper,包含两个:
LambdaQueryWrapperLambdaUpdateWrapper
分别对应QueryWrapper和UpdateWrapper
select id,username,info,balance from user where username like % o% and balance >= 1000 ;
@Test public void test02 () {new LambdaQueryWrapper <>();"o" )1000 );
UPDATE user SET balance = balance - 200 WHERE id in (1 , 2 , 4 );
4.2 自定义SQL
4.2.1 基本使用
在演示UpdateWrapper的案例中,我们在代码中编写了更新的SQL语句:
所以,MybatisPlus提供了自定义SQL功能,可以让我们利用Wrapper生成查询条件,再结合Mapper.xml或注解编写SQL
UPDATE user SET balance = balance - 200 WHERE id in (1 , 2 , 4 )
update user set balance = balance - 200使用注解完成
@Update("update tb_user set balance = balance - #{amount} ${ew.customSqlSegment}") void updateBalanceByWrapper (@Param("amount") int amount, @Param("ew") LambdaQueryWrapper<User> wrapper) ;
where id in(1,2,4) 使用自定义sql完成,将wrapper作为参数传入自定义的方法中${ew.customSqlSegment} ==>where id in (1,2,4)
@Test public void testCustomSql () {int amount = 200 ;new LambdaQueryWrapper <>();1 , 2 , 4 );
4.2.2 多表联查
理论上来将MyBatisPlus是不支持多表查询的,不过我们可以利用Wrapper中自定义条件结合自定义SQL来实现多表查询的效果。
<select id ="queryUserByIdAndAddr" resultType ="com.itheima.mp.domain.po.User" > <foreach collection ="ids" separator ="," item ="id" open ="IN (" close =")" > </foreach > </select >
可以看出其中最复杂的就是WHERE条件的编写,如果业务复杂一些,这里的SQL会更变态。但是基于自定义SQL结合Wrapper的玩法,我们就可以利用Wrapper来构建查询条件,然后手写SELECT及FROM部分,实现多表查询。
@Test void testCustomJoinWrapper () {new QueryWrapper <User>()"u.id" , List.of(1L , 2L , 4L ))"a.city" , "北京" );
然后在UserMapper中自定义方法:
@Select("SELECT u.* FROM user u INNER JOIN address a ON u.id = a.user_id ${ew.customSqlSegment}") queryUserByWrapper (@Param("ew") QueryWrapper<User> wrapper) ;
当然,也可以在UserMapper.xml中写SQL:
<select id ="queryUserByIdAndAddr" resultType ="com.itheima.mp.domain.po.User" > </select >
==总结:where条件可以使用wrapper构建,然后作为参数传递==
4.3 Service接口
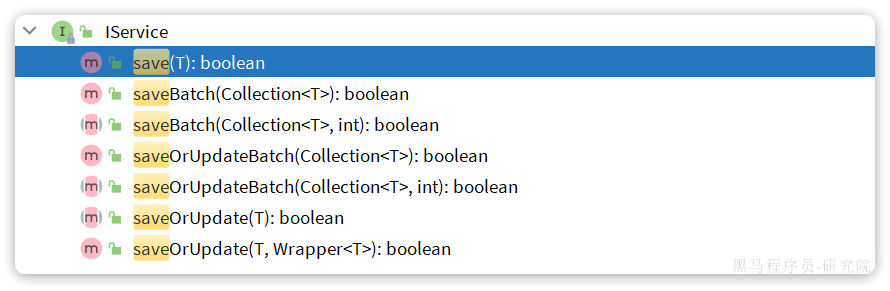
MybatisPlus不仅提供了BaseMapper,还提供了通用的Service接口及默认实现,封装了一些常用的service模板方法。IService,默认实现为ServiceImpl,其中封装的方法可以分为以下几类:
save:新增remove:删除update:更新get:查询单个结果list:查询集合结果count:计数page:分页查询
4.3.1.CRUD
我们先俩看下基本的CRUD接口。新增 :
save是新增单个元素saveBatch是批量新增saveOrUpdate是根据id判断,如果数据存在就更新,不存在则新增saveOrUpdateBatch是批量的新增或修改
删除:
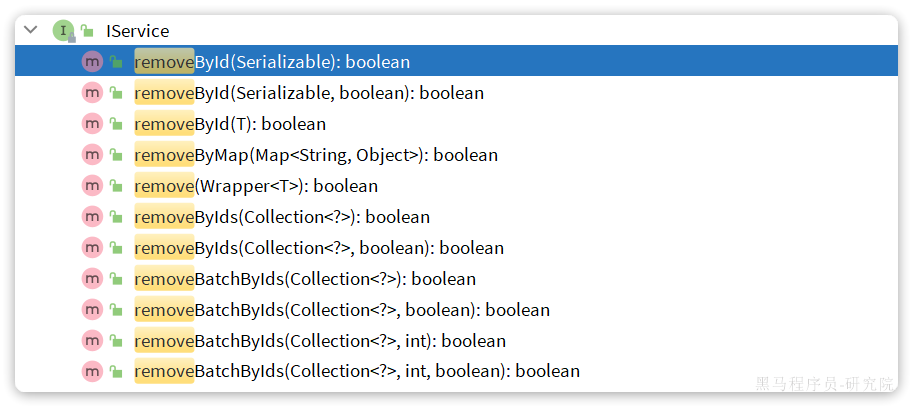
removeById:根据id删除removeByIds:根据id批量删除removeByMap:根据Map中的键值对为条件删除remove(Wrapper<T>):根据Wrapper条件删除~~removeBatchByIds~~:暂不支持
修改:
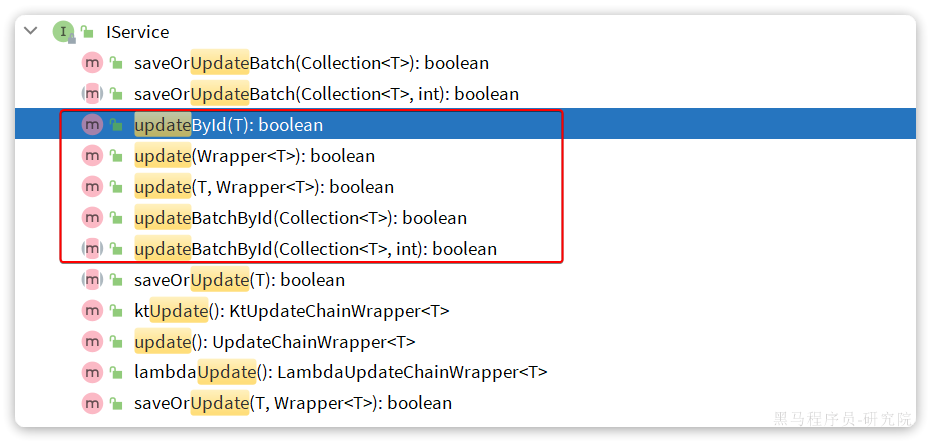
updateById:根据id修改update(Wrapper<T>):根据UpdateWrapper修改,Wrapper中包含set和where部分update(T,Wrapper<T>):按照T内的数据修改与Wrapper匹配到的数据updateBatchById:根据id批量修改
Get:
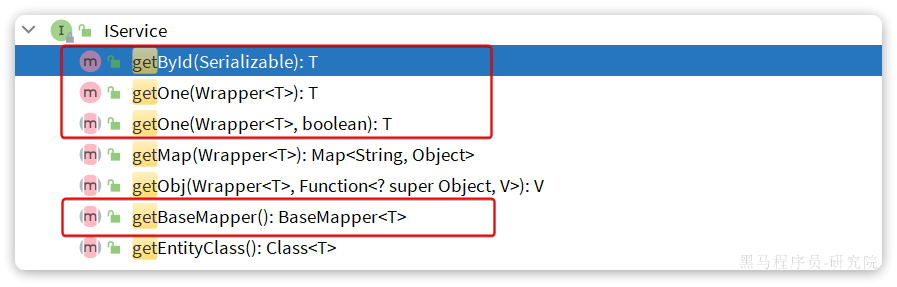
getById:根据id查询1条数据getOne(Wrapper<T>):根据Wrapper查询1条数据getBaseMapper:获取Service内的BaseMapper实现,某些时候需要直接调用Mapper内的自定义SQL时可以用这个方法获取到Mapper
List:
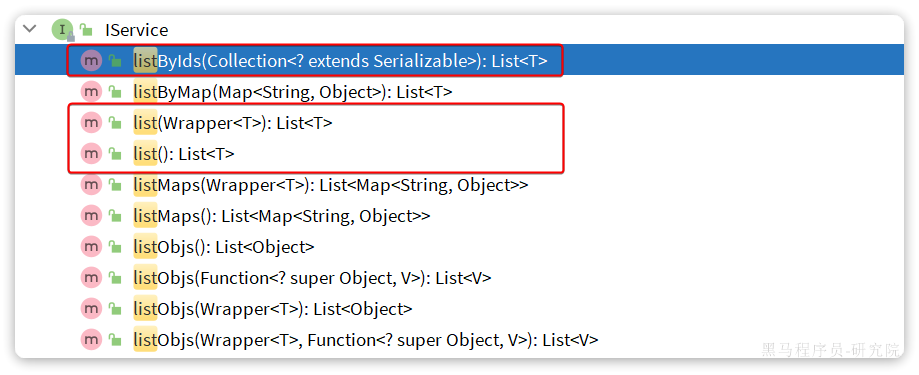
listByIds:根据id批量查询list(Wrapper<T>):根据Wrapper条件查询多条数据list():查询所有
Count :
count():统计所有数量count(Wrapper<T>):统计符合Wrapper条件的数据数量
getBaseMapper :
4.3.2 基本用法
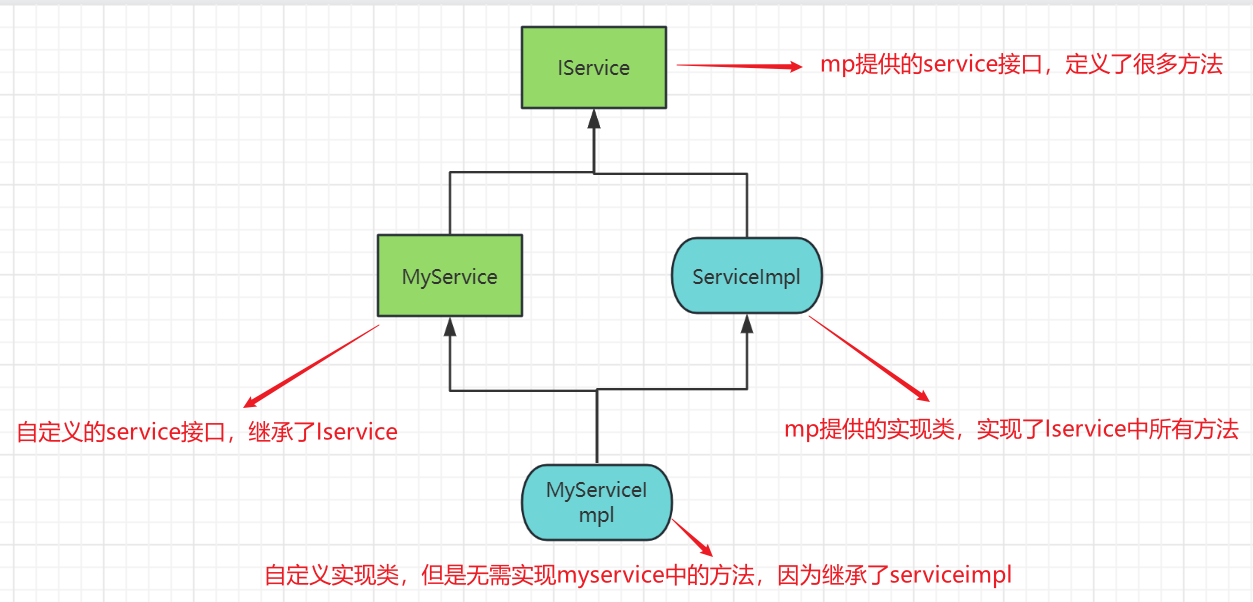
由于Service中经常需要定义与业务有关的自定义方法,因此我们不能直接使用IService,而是自定义Service接口,然后继承IService以拓展方法。同时,让自定义的Service实现类继承ServiceImpl,这样就不用自己实现IService中的接口了,如下图(绿色为接口,蓝色为实现类 )
public interface IUserService extends IService <User>
public class UserServiceImpl extends ServiceImpl <UserMapper, User> implements IUserService
测试
@Test public void testSave () {User user = new User ();"kun_" );"123" );"18688990011" );2000 );24 , "英语老师" , "female" ));@Test public void testGet () {new LambdaQueryWrapper <User>().select(User::getUsername, User::getBalance).le(User::getBalance, 999 ));
4.3.3 批量新增
IService中的批量新增功能使用起来非常方便,但有一点注意事项,我们先来测试一下。
@Test void testSaveOneByOne () {long b = System.currentTimeMillis();for (int i = 1 ; i <= 100000 ; i++) {long e = System.currentTimeMillis();"耗时:" + (e - b));private User buildUser (int i) {User user = new User ();"user_" + i);"123" );"" + (18688190000L + i));2000 );"{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}" );return user;
执行结果如下:
然后再试试MybatisPlus的批处理:
@Test void testSaveBatch () {new ArrayList <>(1000 );long b = System.currentTimeMillis();for (int i = 1 ; i <= 100000 ; i++) {if (i % 1000 == 0 ) {long e = System.currentTimeMillis();"耗时:" + (e - b));
执行最终耗时如下:
不过,我们简单查看一下MybatisPlus源码:
@Transactional(rollbackFor = Exception.class) @Override public boolean saveBatch (Collection<T> entityList, int batchSize) {String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));public static <E> boolean executeBatch (Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {1 , "batchSize must not be less than one" );return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {int size = list.size();int idxLimit = Math.min(batchSize, size);int i = 1 ;for (E element : list) {if (i == idxLimit) {
可以发现其实MybatisPlus的批处理是基于PrepareStatement的预编译模式,然后批量提交,最终在数据库执行时还是会有多条insert语句,逐条插入数据。SQL类似这样:
Preparing: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES ( ?, ?, ?, ?, ?, ?, ? )123 , 18688190001 , "" , 2000 , 2023 -07 -01 , 2023 -07 -01 123 , 18688190002 , "" , 2000 , 2023 -07 -01 , 2023 -07 -01 123 , 18688190003 , "" , 2000 , 2023 -07 -01 , 2023 -07 -01
而如果想要得到最佳性能,最好是将多条SQL合并为一条,像这样:
INSERT INTO user ( username, password, phone, info, balance, create_time, update_time )VALUES 123 , 18688190001 , "", 2000 , 2023 -07 -01 , 2023 -07 -01 ),123 , 18688190002 , "", 2000 , 2023 -07 -01 , 2023 -07 -01 ),123 , 18688190003 , "", 2000 , 2023 -07 -01 , 2023 -07 -01 ),123 , 18688190004 , "", 2000 , 2023 -07 -01 , 2023 -07 -01 );
该怎么做呢?
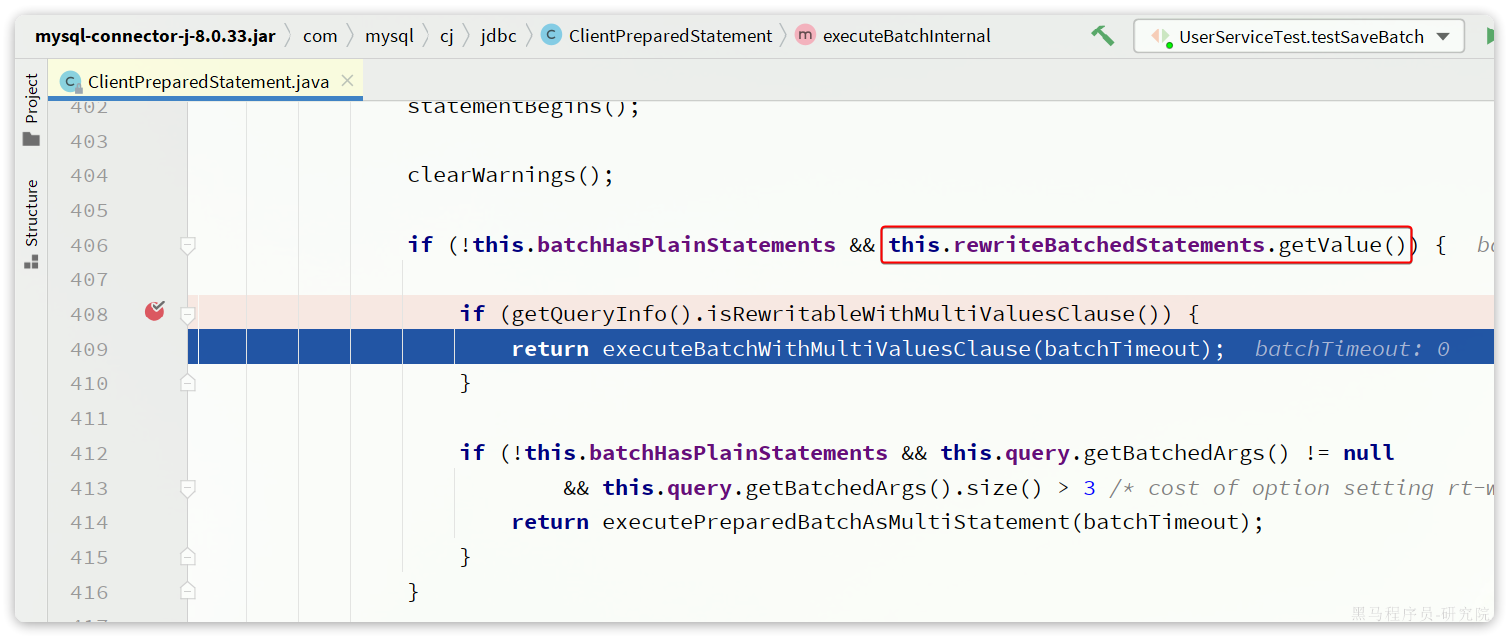
MySQL的客户端连接参数中有这样的一个参数:rewriteBatchedStatements。顾名思义,就是重写批处理的statement语句。参考文档:cj-conn-prop_rewriteBatchedStatements
修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true:
spring: datasource: url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true driver-class-name: com.mysql.cj.jdbc.Driver username: root password: MySQL123
再次测试插入10万条数据,可以发现速度有非常明显的提升:
在ClientPreparedStatement的executeBatchInternal中,有判断rewriteBatchedStatements值是否为true并重写SQL的功能:
总结:
插入大量数据的时候,使用saveBatch批量插入一定数量的数据而不是在循环里面一条一条插入数据save
mysql配置文件中开启批处理
spring: datasource: url: jdbc:mysql://127.0.0.1:3306/mp?rewriteBatchedStatements=true
4.3.4 Lambda
Service中对LambdaQueryWrapper和LambdaUpdateWrapper的用法进一步做了简化。我们无需自己通过new的方式来创建Wrapper,而是直接调用lambdaQuery和lambdaUpdate方法:
基于Lambda查询:
@Test void testLambdaQuery () {User rose = userService.lambdaQuery()"Rose" )"rose = " + rose);"o" )Long count = userService.lambdaQuery()"o" )"count = " + count);
可以发现lambdaQuery方法中除了可以构建条件,而且根据链式编程的最后一个方法来判断最终的返回结果,可选的方法有:
.one():最多1个结果.list():返回集合结果.count():返回计数结果
lambdaQuery还支持动态条件查询。比如下面这个需求:
定义一个方法,接收参数为username、status、minBalance、maxBalance,参数可以为空。
如果username参数不为空,则采用模糊查询;
如果status参数不为空,则采用精确匹配;
如果minBalance参数不为空,则余额必须大于minBalance
如果maxBalance参数不为空,则余额必须小于maxBalance
这个需求就是典型的动态查询,在业务开发中经常碰到,实现如下:
@Test void testQueryUser () {"o" , 1 , null , null );public List<User> queryUser (String username, Integer status, Integer minBalance, Integer maxBalance) {return userService.lambdaQuery()null , User::getUsername, username)null , User::getStatus, status)null , User::getBalance, minBalance)null , User::getBalance, maxBalance)
基于Lambda更新:
@Test void testLambdaUpdate () {800 ) "Jack" )
lambdaUpdate()方法后基于链式编程,可以添加set条件和where条件。但最后一定要跟上update(),否则语句不会执行。
lambdaUpdate()同样支持动态条件,例如下面的需求:
基于IService中的lambdaUpdate()方法实现一个更新方法,满足下列需求:
参数为balance、id、username
id或username至少一个不为空,根据id或username精确匹配用户
将匹配到的用户余额修改为balance
如果balance为0,则将用户status修改为冻结状态
实现如下:
@Test void testUpdateBalance () {0L , 1L , null );public void updateBalance (Long balance, Long id, String username) {0 , User::getStatus, 2 )null , User::getId, id)null , User::getId, username)
4.4.静态工具
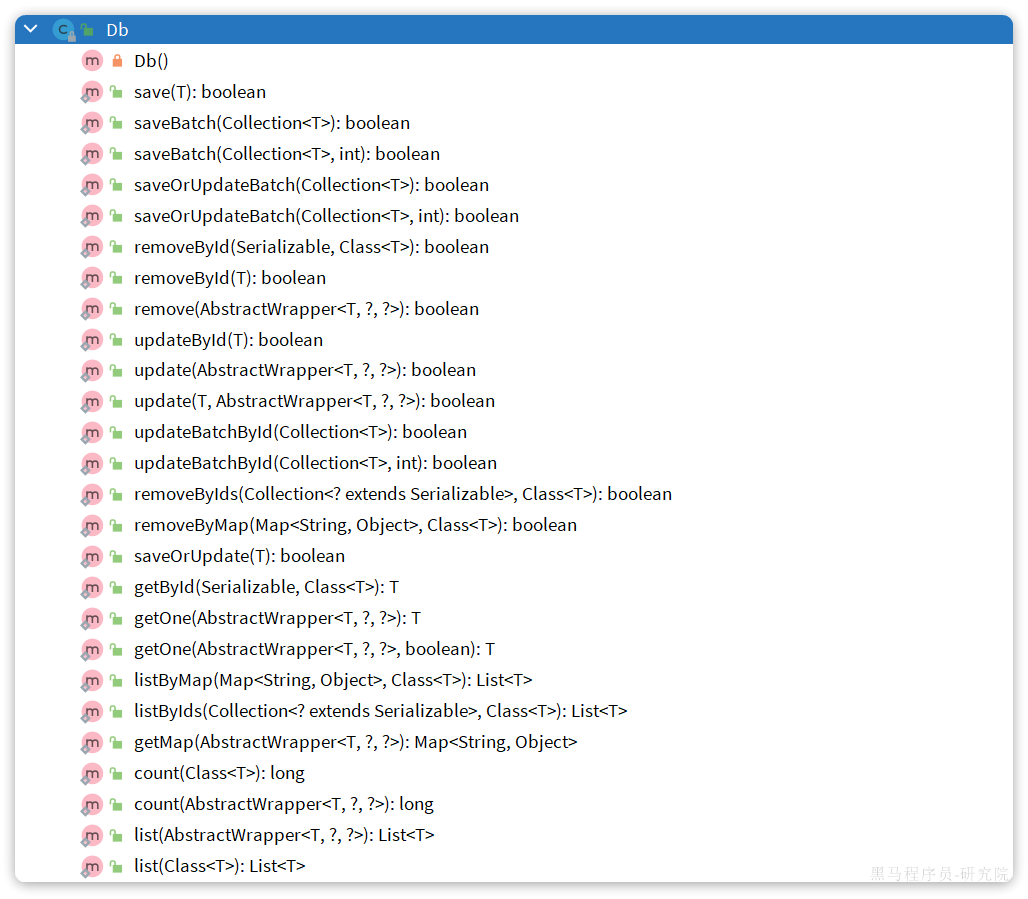
有的时候Service之间也会相互调用,为了避免出现循环依赖问题,MybatisPlus提供一个静态工具类:Db,其中的一些静态方法与IService中方法签名基本一致,也可以帮助我们实现CRUD功能:
示例:
@Test void testDbGet () {User user = Db.getById(1L , User.class);@Test void testDbList () {"o" )1000 )@Test void testDbUpdate () {2000 )"Rose" );
5.拓展功能
5.1 代码生成插件
安装插件
配置数据库
生成代码
5.2 逻辑删除
对于一些比较重要的数据,我们往往会采用逻辑删除的方案,即:
在表中添加一个字段标记数据是否被删除
当删除数据时把标记置为true
查询时过滤掉标记为true的数据
一旦采用了逻辑删除,所有的查询和删除逻辑都要跟着变化,非常麻烦。为了解决这个问题,MybatisPlus就添加了对逻辑删除的支持。注意 ,只有MybatisPlus生成的SQL语句才支持自动的逻辑删除,自定义SQL需要自己手动处理逻辑删除。
例如,我们给address表添加一个逻辑删除字段:
alter table addressadd deleted bit default b'0' null comment '逻辑删除' ;
然后给Address实体添加deleted字段:
接下来,我们要在application.yml中配置逻辑删除字段:
mybatis-plus: global-config: db-config: logic-delete-field: deleted logic-delete-value: 1 logic-not-delete-value: 0
测试:
@Test void testDeleteByLogic () {59L );
方法与普通删除一模一样,但是底层的SQL逻辑变了:
查询一下试试:
@Test void testQuery () {
会发现id为59的确实没有查询出来,而且SQL中也对逻辑删除字段做了判断:
综上, 开启了逻辑删除功能以后,我们就可以像普通删除一样做CRUD,基本不用考虑代码逻辑问题。还是非常方便的。
:::warning注意 :
会导致数据库表垃圾数据越来越多,从而影响查询效率
SQL中全都需要对逻辑删除字段做判断,影响查询效率
因此,我不太推荐采用逻辑删除功能,如果数据不能删除,可以采用把数据迁移到其它表的办法。
5.3 通用枚举
User类中有一个用户状态字段:int类型,对应的PO也是Integer。因此业务操作时必须手动把枚举与Integer转换,非常麻烦。
因此,MybatisPlus提供了一个处理枚举的类型转换器,可以帮我们把枚举类型与数据库类型自动转换 。
5.3.1.定义枚举
我们定义一个用户状态的枚举:
package com.itheima.mp.enums;import com.baomidou.mybatisplus.annotation.EnumValue;import lombok.Getter;@Getter public enum UserStatus {1 , "正常" ),2 , "冻结" )private final int value;private final String desc;int value, String desc) {this .value = value;this .desc = desc;
然后把User类中的status字段改为UserStatus 类型:
要让MybatisPlus处理枚举与数据库类型自动转换,我们必须告诉MybatisPlus,枚举中的哪个字段的值作为数据库值。MybatisPlus提供了@EnumValue注解来标记枚举属性:
5.3.2.配置枚举处理器
在application.yaml文件中添加配置:
mybatis-plus: configuration: default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
5.3.3.测试
@Test void testService () {
最终,查询出的User类的status字段会是枚举类型:
5.4 字段类型处理器
数据库的user表中有一个info字段,是JSON类型:
{ "age" : 20 , "intro" : "佛系青年" , "gender" : "male" }
而目前User实体类中却是String类型:
这样以来,我们要读取info中的属性时就非常不方便。如果要方便获取,info的类型最好是一个Map或者实体类。info改为对象类型,就需要在写入数据库是手动转为String,再读取数据库时,手动转换为对象,这会非常麻烦。
因此MybatisPlus提供了很多特殊类型字段的类型处理器,解决特殊字段类型与数据库类型转换的问题。例如处理JSON就可以使用JacksonTypeHandler处理器。
接下来,我们就来看看这个处理器该如何使用。
5.4.1 定义实体
首先,我们定义一个单独实体类来与info字段的属性匹配:
package com.itheima.mp.domain.po;import lombok.Data;@Data public class UserInfo {private Integer age;private String intro;private String gender;
5.4.2 使用类型处理器
接下来,将User类的info字段修改为UserInfo类型,并声明类型处理器:
测试可以发现,所有数据都正确封装到UserInfo当中了:
5.5配置加密
目前我们配置文件中的很多参数都是明文,如果开发人员发生流动,很容易导致敏感信息的泄露。所以MybatisPlus支持配置文件的加密和解密功能。
我们以数据库的用户名和密码为例。
5.5.1.生成秘钥
首先,我们利用AES工具生成一个随机秘钥,然后对用户名、密码加密:
package com.itheima.mp;import com.baomidou.mybatisplus.core.toolkit.AES;import org.junit.jupiter.api.Test;class MpDemoApplicationTests {@Test void contextLoads () {String randomKey = AES.generateRandomKey();"randomKey = " + randomKey);String username = AES.encrypt("root" , randomKey);"username = " + username);String password = AES.encrypt("MySQL123" , randomKey);"password = " + password);
打印结果如下:
randomKey = 6234633a66fb399f username = px2bAbnUfiY8K/IgsKvscg==
5.5.2.修改配置
修改application.yaml文件,把jdbc的用户名、密码修改为刚刚加密生成的密文:
spring: datasource: url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true driver-class-name: com.mysql.cj.jdbc.Driver username: mpw:QWWVnk1Oal3258x5rVhaeQ== password: mpw:EUFmeH3cNAzdRGdOQcabWg==
5.5.3.测试
在启动项目的时候,需要把刚才生成的秘钥添加到启动参数中,像这样:
--mpw.key=6234633a66fb399f
单元测试的时候不能添加启动参数,所以要在测试类的注解上配置:
然后随意运行一个单元测试,可以发现数据库查询正常。
6.插件功能
MybatisPlus提供了很多的插件功能,进一步拓展其功能。目前已有的插件有:
PaginationInnerInterceptor:自动分页TenantLineInnerInterceptor:多租户DynamicTableNameInnerInterceptor:动态表名OptimisticLockerInnerInterceptor:乐观锁IllegalSQLInnerInterceptor:sql 性能规范BlockAttackInnerInterceptor:防止全表更新与删除
:::warning注意:
多租户,动态表名
分页,乐观锁
sql 性能规范,防止全表更新与删除
:::
这里我们以分页插件为里来学习插件的用法。
6.1.分页插件
在未引入分页插件的情况下,MybatisPlus是不支持分页功能的,IService和BaseMapper中的分页方法都无法正常起效。
6.1.1.配置分页插件
在项目中新建一个配置类:
package com.itheima.mp.config;import com.baomidou.mybatisplus.annotation.DbType;import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configuration public class MybatisConfig {@Bean public MybatisPlusInterceptor mybatisPlusInterceptor () {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor ();new PaginationInnerInterceptor (DbType.MYSQL));return interceptor;
6.1.2.分页API
编写一个分页查询的测试:
@Test void testPageQuery () {new Page <>(2 , 2 ));"total = " + p.getTotal());"pages = " + p.getPages());
运行的SQL如下:
这里用到了分页参数,Page,即可以支持分页参数,也可以支持排序参数。常见的API如下:
int pageNo = 1 , pageSize = 5 ;new OrderItem ("balance" , false ));
6.2.通用分页实体
现在要实现一个用户分页查询的接口,接口规范如下:
参数 说明
请求方式
GET
请求路径
/users/page
请求参数
```json
{
“pageNo”: 1,
“pageSize”: 5,
“sortBy”: “balance”,
“isAsc”: false
}
{ "total" : 100006 , "pages" : 50003 , "list" : [ { "id" : 1685100878975279298 , "username" : "user_9****" , "info" : { "age" : 24 , "intro" : "英文老师" , "gender" : "female" } , "status" : "正常" , "balance" : 2000 } , { "id" : 1685100878975279299 , "username" : "user_9****" , "info" : { "age" : 24 , "intro" : "英文老师" , "gender" : "female" } , "status" : "正常" , "balance" : 2000 } ] }
|
这里需要定义3个实体:
PageQuery:分页查询条件的实体,包含分页、排序参数PageDTO:分页结果实体,包含总条数、总页数、当前页数据UserVO:用户页面视图实体
接下来我们就按照WEB开发的过程来实现这个接口。spring-boot-starter-web依赖:
<dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-web</artifactId > </dependency > <dependency > <groupId > cn.hutool</groupId > <artifactId > hutool-all</artifactId > <version > 5.8.11</version > </dependency >
然后,按alt+8打开service控制台,然后添加一个SpringBoot启动项:Spring Boot:
6.2.1.实体
首先是请求参数的PageQuery实体:PageQuery是前端提交的查询参数,一般包含四个属性:
pageNo:页码pageSize:每页数据条数sortBy:排序字段isAsc:是否升序
package com.itheima.mp.domain.query;import lombok.Data;@Data public class PageQuery {private Integer pageNo;private Integer pageSize;private String sortBy;private Boolean isAsc;
然后我们定义一个UserVO实体:
package com.itheima.mp.domain.vo;import com.itheima.mp.domain.po.UserInfo;import com.itheima.mp.enums.UserStatus;import lombok.Data;@Data public class UserVO {private Long id;private String username;private UserInfo info;private UserStatus status;private Integer balance;
最后,则是分页实体PageDTO:
代码如下:
package com.itheima.mp.domain.dto;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import java.util.List;@Data @NoArgsConstructor @AllArgsConstructor public class PageDTO <T> {private Integer total;private Integer pages;private List<T> list;
6.2.2.开发接口
我们定义一个UserController,在controller中我们定义分页查询用户的接口:
package com.itheima.mp.controller;import com.itheima.mp.domain.dto.PageDTO;import com.itheima.mp.domain.query.PageQuery;import com.itheima.mp.domain.vo.UserVO;import com.itheima.mp.service.UserService;import lombok.RequiredArgsConstructor;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestController @RequestMapping("users") @RequiredArgsConstructor public class UserController {private final UserService userService;@GetMapping("/page") public PageDTO<UserVO> queryUserByPage (PageQuery query) {return userService.queryUserByPage(query);
然后在UserService中创建queryUserByPage方法:
PageDTO<UserVO> queryUserByPage (PageQuery query) ;
接下来,在UserServiceImpl中实现该方法:
@Override public PageDTO<UserVO> queryUserByPage (PageQuery query) {if (query.getSortBy() != null ) {new OrderItem (query.getSortBy(), query.getIsAsc()));else {new OrderItem ("update_time" , false ));if (records == null || records.size() <= 0 ) {return new PageDTO <>(page.getTotal(), page.getPages(), Collections.emptyList());return new PageDTO <UserVO>(page.getTotal(), page.getPages(), list);
最后,为了让UserStatus枚举可以展示为文字描述,再给UserStatus中的desc字段添加@JsonValue注解:
6.2.3.改造PageQuery实体
在刚才的代码中,从PageQuery到MybatisPlus的Page之间转换的过程还是比较麻烦的。PageQuery这个实体中定义一个工具方法,简化开发。
package com.itheima.mp.domain.query;import com.baomidou.mybatisplus.core.metadata.OrderItem;import com.baomidou.mybatisplus.extension.plugins.pagination.Page;import lombok.Data;@Data public class PageQuery {private Integer pageNo;private Integer pageSize;private String sortBy;private Boolean isAsc;public <T> Page<T> toMpPage (OrderItem ... orders) {if (sortBy != null ) {new OrderItem (sortBy, isAsc));return p;if (orders != null ){return p;public <T> Page<T> toMpPage (String defaultSortBy, boolean isAsc) {return this .toMpPage(new OrderItem (defaultSortBy, isAsc));public <T> Page<T> toMpPageDefaultSortByCreateTimeDesc () {return toMpPage("create_time" , false );public <T> Page<T> toMpPageDefaultSortByUpdateTimeDesc () {return toMpPage("update_time" , false );
这样我们在开发也时就可以省去对从PageQuery到Page的的转换:
6.2.4.改造PageDTO实体
在查询出分页结果后,数据的非空校验,数据的vo转换都是模板代码,编写起来很麻烦。
我们完全可以将其封装到PageDTO的工具方法中,简化整个过程:
package com.itheima.mp.domain.dto;import cn.hutool.core.bean.BeanUtil;import com.baomidou.mybatisplus.extension.plugins.pagination.Page;import lombok.AllArgsConstructor;import lombok.Data;import lombok.NoArgsConstructor;import java.util.Collections;import java.util.List;import java.util.function.Function;import java.util.stream.Collectors;@Data @NoArgsConstructor @AllArgsConstructor public class PageDTO <V> {private Long total;private Long pages;private List<V> list;public static <V, P> PageDTO<V> empty (Page<P> p) {return new PageDTO <>(p.getTotal(), p.getPages(), Collections.emptyList());public static <V, P> PageDTO<V> of (Page<P> p, Class<V> voClass) {if (records == null || records.size() <= 0 ) {return empty(p);return new PageDTO <>(p.getTotal(), p.getPages(), vos);public static <V, P> PageDTO<V> of (Page<P> p, Function<P, V> convertor) {if (records == null || records.size() <= 0 ) {return empty(p);return new PageDTO <>(p.getTotal(), p.getPages(), vos);
最终,业务层的代码可以简化为:
@Override public PageDTO<UserVO> queryUserByPage (PageQuery query) {return PageDTO.of(page, UserVO.class);
如果是希望自定义PO到VO的转换过程,可以这样做:
@Override public PageDTO<UserVO> queryUserByPage (PageQuery query) {return PageDTO.of(page, user -> {UserVO vo = BeanUtil.copyProperties(user, UserVO.class);String username = vo.getUsername();0 , username.length() - 2 ) + "**" );return vo;
最终查询的结果如下: